



06/09/2010
Questions pièges Java n°6
Double question !
Question 6a :
Qu'affiche le code suivant (à supposer que la fonction main soit effectivement exécutée) :
class Base{
{ System.out.print ( "A"); };
Base( ) { System.out.print ("B"); }
}
class Derived extends Base{
{ System.out.print ("C"); };
Derived ( ) {
this ( 0 );
System.out.print ("D");
}
Derived ( int i ) {
System.out.print ("E");
}
{ System.out.print ("F"); };
}
public class AClass {
public static void main(String[ ] args){
Derived c = new Derived( );
}
}Question 6b :
Qu'affiche le code suivant (à supposer que la fonction main soit effectivement exécutée) :
class Base {
Base ( ) {init ( ); }
void init ( ) { System.out.println(2); }
}
class Derived extends Base{
int i = 4;
final int j = 4;
void init() { System.out.println ( i +" "+j); }
}
public class AClass {
public static void main(String[ ] args){
Derived c = new Derived( );
}
}15:29 | Lien permanent | Commentaires (0) | Tags : java1.5, question piège
04/09/2010
Performances des communication inter-thread
Le débat :
Cette note fait suite à une discussion que nous avons eu un ami et moi, sur la recherche de performances dans la communication inter-(thread/process/programmes). Selon lui, et il sait de quoi il parle, le moyen le plus rapide consiste à passer par la mémoire (préférentiellement aux pipes en particulier).
Partant de là, la question s'est posée d'utiliser ou non des files bloquantes ou non-bloquante.
En effet, pour un peu que l'on travaille correctement, les files ne doivent servir qu'à transférer des pointeurs un petit peu plus intelligents que les autres, c'est à dire qui veillent à n'appartenir qu'à un seul thread/process/programme à la fois.
L'opération de lecture/écriture dans la fifo ne concerne donc qu'un unique pointeur et se doit donc d'être très rapide, et on peut légitimement se poser la question : dans quelle mesure vais-je gagner des performances à mettre en place un système de fifo non-bloquantes ?
Le programme :
Le programme inclus dans ce post permet d'avancer dans ce débat.
Voici ce qu'il fait :
1. il crée n files (qui peuvent contenir des entiers)
2. pour chaque file, il crée nw threads qui vont écrire dedans et nr threads qui vont lire dedans
3. il demande à tous ces threads de lire/ecrire pendant t secondes
4. il compte les entiers qui ont été écris/lus, ceux qui sont restés dans la file, ceux qui ne sont jamais arrivés et ceux qui sont arrivés erronés.
Bien sur, n, nw, nr et t sont paramétrables, ainsi que :
- un temps supplémentaire que l'on peut ajouter pendant lequel les threads d'écriture s'arrettent, mais pas ceux de lecture
- un temps de pause (sleep) des threads d'écriture après chaque écriture
- un temps de pause (sleep) des threads de lecture après chaque lecture infructueuse (la file est vide)
- le type de file
Pour le premier test, je n'ai utilisé que deux types de file, tous deux très simples (on ne le répètera jamais : "First, make it work !") :
- une std::queue à laquelle j'ai simplement rajouté un boost::mutex (ce qui est probablement ce que ferait n'importe qui en première approche)
- un tableau statique de 100 éléments (dans lequel on lit et on écrit de manière circulaire)
Les défauts, et pourquoi ils ne me gênent pas :
1. le tableau circulaire n'est pas thread-safe, mais pour ma démonstration, il me suffit.
Je me permet en effet de supposer que toute file threadsafe et non-bloquante sera plus lente que mon "circlingarray".
Autrement dit : si je montre que le gain de performance avec ce tableau n'est pas intéressant, j'ai peu de chance de trouver un autre type de file threadsafe qui soit intéressant.
A supposer que cette hypothèse soit fausse : il suffit d'insérer cet autre type de thread dans le programme et de relancer les tests.
2. La question du redimensionnement des files pendant l'exécution n'est pas abordée ici, elle est trop spécifique et trop complexe pour un petit exemple tel que celui-ci. De façon générale, je me permet de supposer que :
- soit notre programme essaie de résoudre un problème que l'on sait bien dimensionner, auquel cas le redimensionnement ne nous intéresse qu'à la marge
- soit notre programme essaie de résoudre un problème que l'on ne sait pas dimensionner, auquel cas l'urgence n'est sans doute pas de gagner quelques millisecondes sur la communication entre les threads.
Dans tous les cas, ma std::queue se redimensionne toute seule, alors que mon CirclingArray est statique. Si je montre que le CirclingArray n'est pas intéressant. A fortiori, une version redimensionnable du CirclingArray ne le serait pas plus.
Autre argument : on essaie ici de gagner des millisecondes. Si notre fifo se remplit tellement qu'elle dépasse la taille pré-définie, il y a très peu de chance que les derniers éléments soient traités rapidement. A ce moment-là, il vaut mieux sans doute mieux augmenter le nombre de lecteurs ou améliorer la vitesse de traitement des lecteurs, et ne pas incriminer la file.
3. La vérification des entiers qui ont traversé la file se fait sur leur valeur. Cette méthode n'est pas parfaite, car, si ma file transforme un 1 en 2 et un 2 en 1, le programme considère qu'il n'y a pas d'erreur. Je m'autorise à estimer que ce phénomène reste marginal, et qu'en général, ma file transformera un 1 en -27654098756 ou quelque chose de tout aussi reconnaissable.
4. Les threads de lecture/ecriture ne font rien d'autre que lire et écrire. Là encore, je choisis le cas le pire. Dans un cas réel, les threads seraient occupés deux lecture/écriture, mais alors le besoin de performance serait moindre.
5. Ce programme ne gère pas les erreurs graves (SegFault, Stack Overflow, Exception non-catchée ...) provoquées par les files. Autrement dit, on ne peut pas tout tester. En particulier, on ne peut pas utiliser de std::queue non protégée par des mutex. J'avoue ne pas avoir d'idée simple à mettre en œuvre pour gérer ces problèmes. On pourrait sans doute mettre en place quelque chose à partir de machines virtuelles, mais les performances mesurées n'auraient alors plus le moindre sens.
Les résultats :
Voici les premiers résultats : 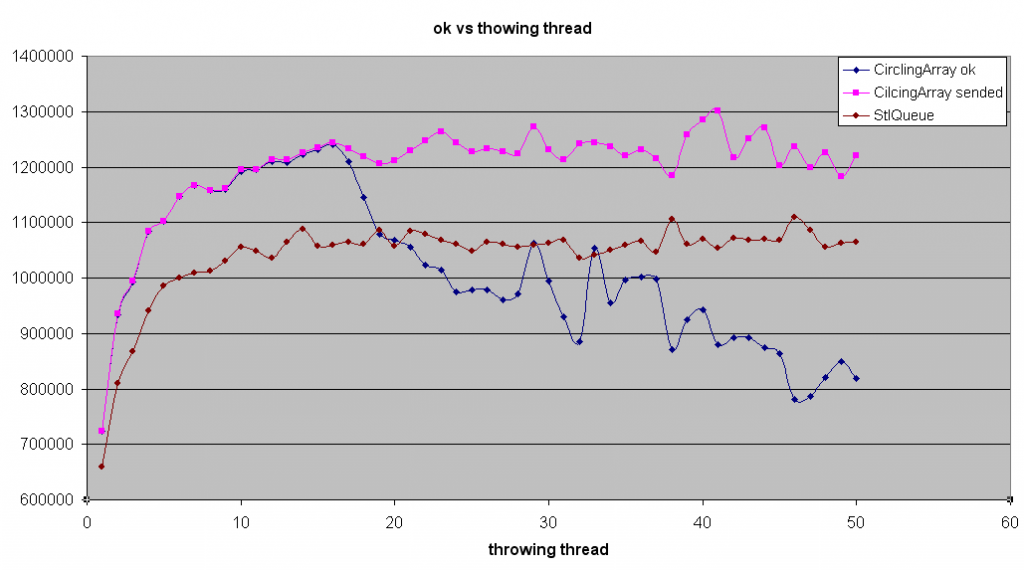
Ces résultats ont été obtenus pour :
- 10 files simultanées
- 1 thread de lecture par file
- x threads d'écriture par file (x étant l'abscisse des courbes de résultats)
- 1 seconde de test
- 0 secondes additionnelles
- 0 ms de pause pour l'écriture
- 0 ms de pause pour la lecture
Voici un deuxième jeu de résultat : 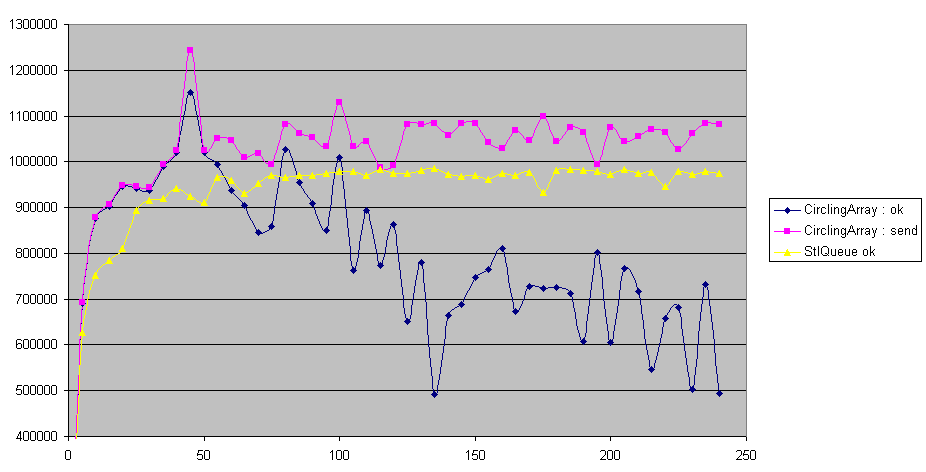
Ces résultats ont été obtenus pour :
- 1 files unique
- 5 threads de lecture par file
- x threads d'écriture par file (x étant l'abscisse des courbes de résultats)
- 1 seconde de test
- 0 secondes additionnelles
- 0 ms de pause pour l'écriture
- 0 ms de pause pour la lecture
Bien sur, ces résultats dépendent très largement de la machine que vous utilisez pour les tests.
Mes observations sur ces résultats :
1. le circling array est au mieux 20% plus efficace que la std::queue
2. pour les deux types de files, le nombre d'entiers envoyés augmente sur une plage avec le nombre de threads d'écriture, jusqu'à atteindre un maximum à partir duquel il est relativement stable
3. dans tous les cas aucun entier ne reste coincé dans les files. Ceci est étrange, il se peut qu'y ait un problème de conception dans mon programme quelque part : les threads de lecture sont-ils trop rapides ? le comptage des entiers coincés dans la file est-il défaillant ?
4. comme on s'y attendait : le circlingArray fait beaucoup d'erreur quand il est plein, mais finalement pas tant que cela quand il est vide.
5. le premier point de ces courbes montre que le CirclingArray semble (conformément notre intuition) threadsafe dans le cas où il n'y a qu'un thread qui lit et qu'un thread qui écrit. D'autres résultats (non-communiqués ici) vont dans ce sens (0 erreurs pour 5 millions d'entiers transférés).
Les Conclusions :
J'en conclus donc que l'utilisation des files non-bloquantes ne sera pas, en général, un vecteur de gain de performance important. En tout cas pas sur la machine à partir de laquelle j'ai fait ces tests. Il ne coûte pas grand chose de relancer les test à partir de la machine cible
Télécharger les sources
Note 1 : pour compiler le code ci-joint, vous aurez besoin de boost, y compris de boost.thread et de boost.program_options qui doivent être compilés.
Note 2 : merci de votre indulgence quand à ce code, il comporte de vrais défauts connus (et sans doute d'autres inconnus), mais nous sommes dans le cadre de la création d'un programme "jetable", et surtout d'un travail personnel réalisé sur mon temps libre. On ne le répètera jamais assez : "First : make it work" et "Don't be afraid of refactoring".
Défaut connu 1 : J'ai un peu réinventé la roue pour les logs, je me suis laissé prendre au jeu. En effet, je voulais des logs statiques (activable/désactivables à la compilation) pour ne pas gêner les performances. Donc je n'ai pas utilisé ceci .
Défaut connu 2 : Pour les logs, j'ai surchargé "Log
Défaut connu 3 : Je n'ai pas trouvé de méthode standard dans boost.program_options pour lui demander de me cracher un enum. J'ai donc codé à la main (en vitesse) une solution spécifique (template tout de même, elle s'adapte à tous les enums). Mais en terme de méthodologie, ce n'est pas satisfaisant.
Défaut connu 4 : Certaines classes présentent des méthodes avec beaucoup trop de paramètres. Une solution plus élégante aurait consisté à transformer ces paramètres en attributs de la classe. Mais à ce moment-là il aurait fallu faire en sorte que ces classes sachent détecter l'absence d'un attribut et (pour faire les choses bien) soient capable de se remettre dans un état utilisable une fois leur fonction remplie. C'était du travail (et donc du temps), et cela ne m'était pas utile dans le cadre de ce programme.
Défaut connu 5 : Les thread de lecture stoquent tous les entiers lus (au lieu de les compiler au fur et à mesure). C'est à dire qu'ils utilisent une std::list
FIFO_tests.zip
17:34 | Lien permanent | Commentaires (0) | Tags : c++
23/06/2010
Point théorique Java : Enchainements de conversion
Les enchainements de conversions autorisés lors d'une assignation, d'un passage de paramètre ou d'une opération sont :
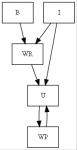
Légende :
// I = identity
// WP = Widening primitive
// WR = Widening reference
// B = Boxing
// U = Unboxing
Ainsi on peut écrire :
Number n = 4; //(Boxing en Integer -> Widening reference)
Objet o = 4; //(id)
long l = (Integer)4; //(Unboxing -> de Widening primitive)
De la même facon
// même chose pour un passage de paramètre
MethodQuiAttendUnObject(4);
// même chose pour une opération
long l = ((Integer)4 + 7);
Mais on ne peut toujours pas écrire :
Long l = 4; //(widening reference -> Boxing) est interdit
En pratique ces exemples semblent être les seuls cas intéressants.
(*) Identity est la conversion qui transforme un type en lui même.
Le fait que ce soit autorisé permet parfois de rendre le code plus lisible ex :
{
int quelquechose = 4;
... un grand nombre de lignes de code sans utiliser la variable quelquechose;
(int)quelquechose += 5;
}
14:22 | Lien permanent | Commentaires (0) | Tags : java1.5, point théorique